
What Is an LLM, and How Do You Pick the Right One for Your Business?
If you’ve spent any time in the tech world over the last couple of years, you’ve heard the term “LLM” thrown around constantly. Large language models power ChatGPT, Claude, Gemini, and pretty much every AI assistant that’s become part of our daily vocabulary. But what actually is an LLM, and more importantly, how do you figure out which one is right for your specific business problem?
Let me break it down in plain terms:
The short version of what an LLM actually does
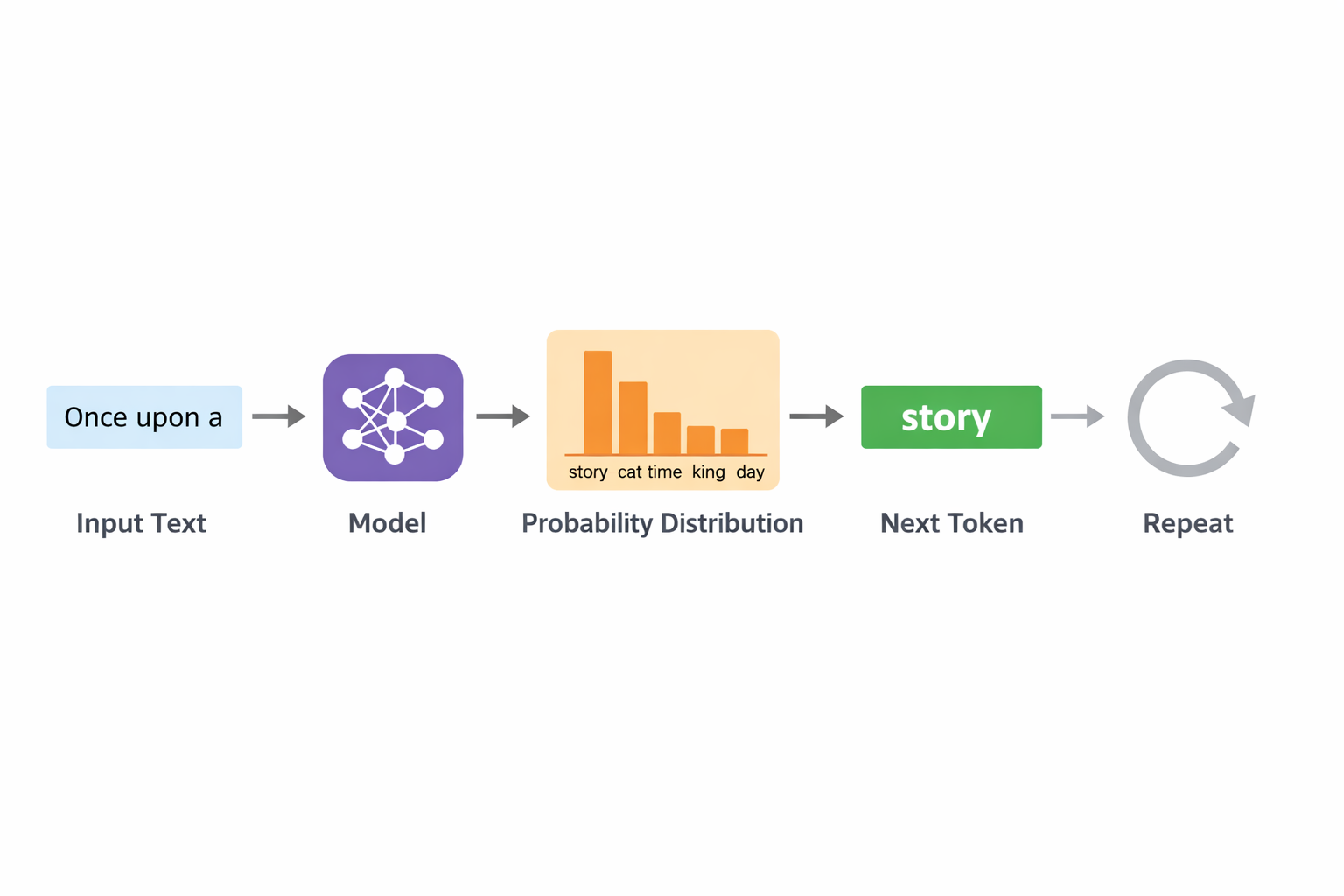
At its core, a large language model is a neural network trained to predict the next word (or more precisely, the next “token”) in a sequence. Feed it billions of web pages, books, articles, and code, and it learns the statistical patterns of human language: syntax, semantics, context, even some reasoning.
When you ask it a question, it’s not “looking up” an answer the way a search engine does. It’s generating a response one token at a time, based on what it has learned is most likely to follow. That’s why these models can write, summarize, explain, and even code, but it’s also why they can confidently say something wrong. The model doesn’t know what’s true; it knows what sounds like a plausible continuation of text.
That distinction matters enormously when you’re thinking about applying LLMs to business processes.
Pre-training vs. post-training: why this affects you
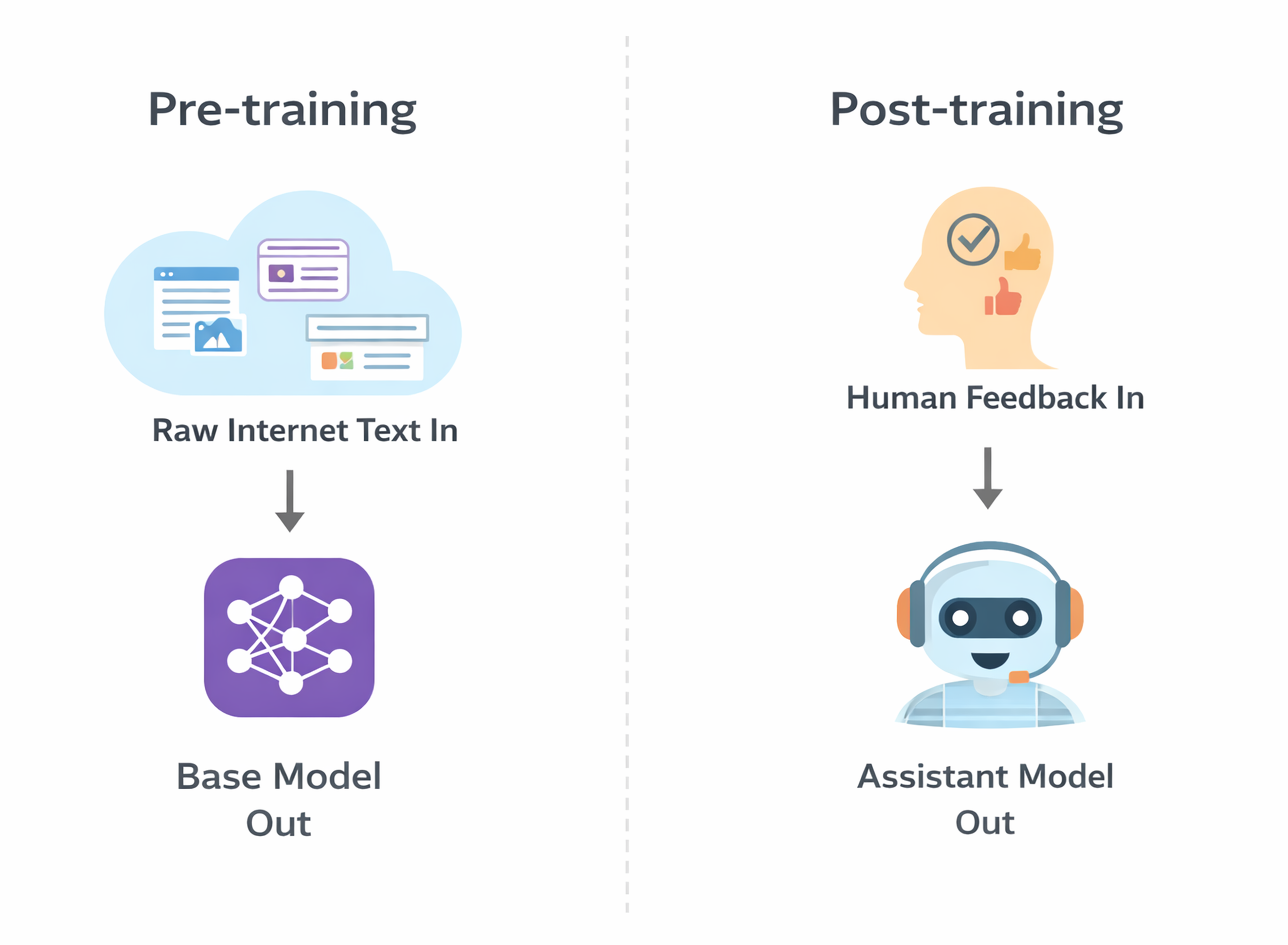 Most LLMs go through two phases. First, pre-training: the model ingests a massive corpus of internet text and learns to predict language patterns. This is where the bulk of what the model “knows” comes from. Think GPT-3 or the base LLaMA models, which are powerful but not yet useful as a business tool.
Most LLMs go through two phases. First, pre-training: the model ingests a massive corpus of internet text and learns to predict language patterns. This is where the bulk of what the model “knows” comes from. Think GPT-3 or the base LLaMA models, which are powerful but not yet useful as a business tool.
The second phase is post-training, which is where the model gets shaped into an assistant. Through a combination of human feedback, preference ranking, and fine-tuning on curated examples, the model learns to follow instructions, stay helpful, and avoid harmful outputs. This is what separates ChatGPT from a raw language model.
Why does this matter for you? Because the post-training process reflects choices made by the model’s developers: what’s acceptable, what’s prioritized, what use cases it’s been optimized for. Two models might have similar raw capability but behave very differently in a production environment.
Picking the right LLM for your use case
 Here’s where a lot of organizations go wrong: they evaluate models by running one or two informal tests, pick a winner, and move on. That’s how you end up with a tool that performs beautifully in the demo and falls apart in production.
Here’s where a lot of organizations go wrong: they evaluate models by running one or two informal tests, pick a winner, and move on. That’s how you end up with a tool that performs beautifully in the demo and falls apart in production.
A few things worth considering:
- Benchmark results are context-dependent. The same model can score very differently across evaluation frameworks. A 63% accuracy on one benchmark can drop to 48% on another, not because the model changed, but because the evaluation method changed. Don’t put too much stock in a single leaderboard ranking.
- Longer outputs aren’t better outputs. Both humans and AI evaluation tools have a documented bias toward longer responses. When evaluating models, make sure you’re scoring for accuracy and usefulness, not verbosity. Some of the best business-ready responses are concise and precise, not sprawling.
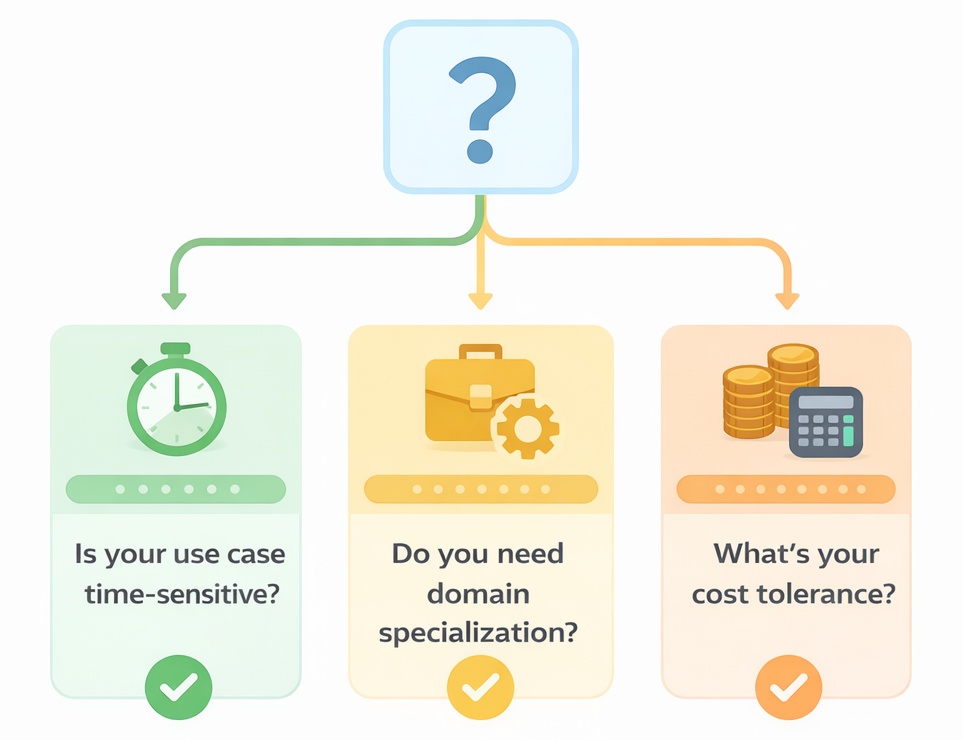
- Training data cutoffs matter. If your use case involves recent events, current market data, or anything time-sensitive, you need a model with web access or recent training data. A model with a knowledge cutoff from a year ago can’t help you analyze last quarter’s trends.
- Understand the difference between general and fine-tuned models. A general-purpose LLM like Claude or GPT-4 is remarkably capable out of the box. But for highly specialized domains like legal analysis, medical documentation, or financial compliance, you may get better results from a fine-tuned model trained specifically on that domain’s language and conventions.
- Cost and inference time are real considerations. The biggest model isn’t always the right model. For tasks like summarization, classification, or drafting routine communications, smaller, faster, cheaper models often perform comparably to the frontier models. Right-sizing your model to the task can dramatically change your economics.
The practical bottom line
After watching this space evolve for several years, the organizations getting the most value from LLMs are the ones doing three things consistently:
- Defining specific, measurable success criteria before evaluating any model
- Testing against real data from their own domain rather than generic demos
- Building feedback loops so they know when model performance degrades over time
The model isn’t the whole answer. How you prompt it, what data you give it access to, and how you evaluate its outputs matter just as much. But starting with the right LLM, matched to your actual use case, is step one.
If you’re looking to improve your AI skills and get more out of the platform you use, take a look at my course on Practical Prompt Engineering.

